Tema 6:Configuración y administración de protocolos dinámicos
Protocolos enrutables y protocolos de enrutamiento.
En las redes hemos usado muy a menudo el concepto de protocolo:
Por ejemplo IP establece que las direcciones tienen que tener un cierto formato, que tienen que tener una máscara y que no debe haber dos nodos con la misma IP (aparte de muchas otras reglas).
Protocolos como HTTP dicen que para descargar un archivo se debe enviar la cadena
GET /archivo.html
En principio tendemos a pensar que un protocolo nos permite comunicar con cualquier máquina pero esto no es así: no todos los protocolos están pensados para comunicar con máquinas más alla de nuestro router. A estos protocolos se les llama protocolos no enrutables.
Un buen ejemplo de esto es el protocolo para carpetas compartidas en Windows o para descubrir otros equipos en la red (lo que usamos al «explorar la red de Windows»).
Por supuesto, los protocolos de nivel de enlace (también llamado de capa 2 o L2) no son enrutados por los routers. De hecho, si lo fueran, el más minimo ping podría generar difusiones que alcanzarían a todo Internet (lo cual es un buen motivo para no enrutarlos).
En suma, cuando trabajamos con redes, especialmente con redes «Windows» debemos tener presente que en principio no podremos contactar con otras redes remotas Windows.
Funcionamiento de los protocolos de enrutamiento dinámico.
Este punto no es estrictamente parte del temario. Sin embargo, se incluye para entender mejor como funcionan los procesos por los cuales un router puede «aprender» rutas a redes remotas.
En primer lugar, todos los router anuncian todo lo que saben. Normalmente, al principio solo conocen a las redes con las que tienen conexión directa. En la figura ponemos solo un router, pero esto ocurre con la mayor parte de procesos de enrutamiento dinámico (de hecho hay pequeños casos en los que un router configurado con enrutamiento dinámico no haría nada)
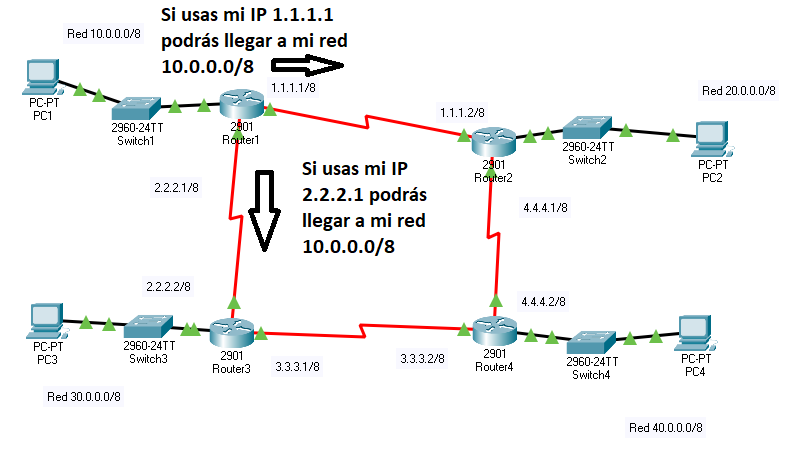
Esta información llega a los router «Router 2» y «Router 3», los cuales se apuntan la información en sus tablas de rutas. Ahora «Router 2» tiene esto
Red |
Máscara |
Siguiente salto |
Métrica |
|---|---|---|---|
10.0.0.0 |
255.0.0.0 |
1.1.1.1 |
1 |
Y «Router 3» tiene esto:
Red |
Máscara |
Siguiente salto |
Métrica |
|---|---|---|---|
10.0.0.0 |
255.0.0.0 |
2.2.2.1 |
1 |
Es evidente que en el primer paso, todos los router aprenderán como llegar a redes que estén a un «salto» de distancia. Pasado un cierto tiempo, todos los router vuelven a anunciar todo lo que saben. Fijémenos en lo que anuncia «Router 2»
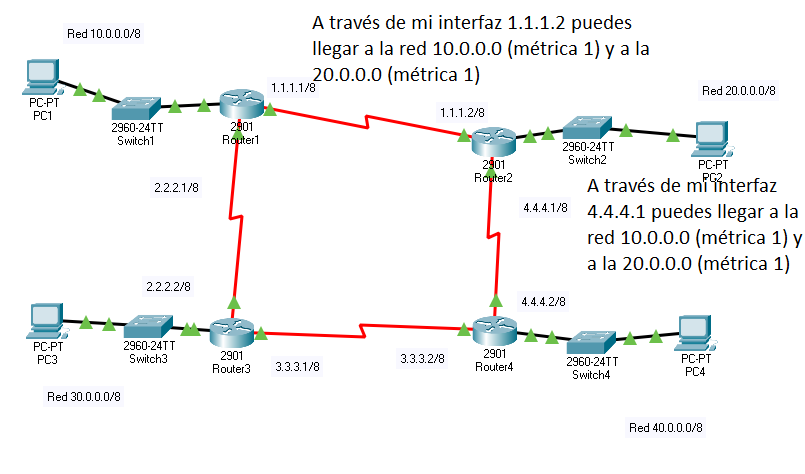
Sin embargo, ahora «Router 1» recibe una información que no necesitaba:
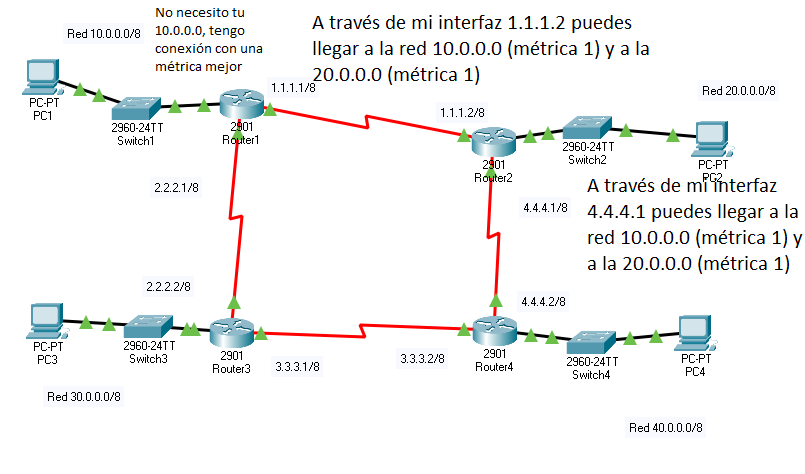
Por el contrario «Router 4» recibe información nueva que no tenía, cosa de la que tomará nota en su tabla de rutas
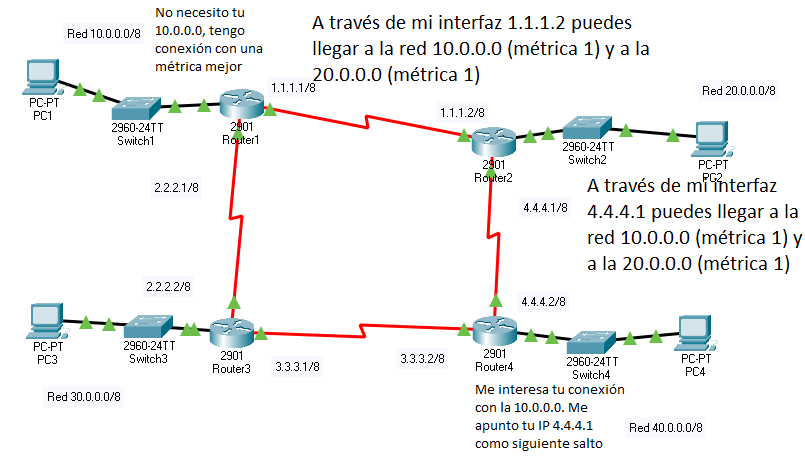
De hecho, en solo dos pasos, la tabla de «Router 4» será más o menos así. En la tabla siguiente NO PONEMOS todas las rutas a todos los sitios, ya que algunas eran «peores». Recalcamos sin embargo, que ahora hay dos caminos para la 10.0.0.0:
Red |
Máscara |
Siguiente salto |
Métrica |
Aprendida mediante |
|---|---|---|---|---|
10.0.0.0 |
255.0.0.0 |
3.3.3.1 |
2 |
Router3 |
10.0.0.0 |
255.0.0.0 |
4.4.4.1 |
2 |
Router2 |
20.0.0.0 |
255.0.0.0 |
4.4.4.1 |
1 |
Router2 |
30.0.0.0 |
255.0.0.0 |
3.3.3.1 |
1 |
Router3 |
Protocolos de enrutamiento interior y exterior.
Concepto de sistema autónomo
El RFC 1930 define un sistema autónomo como:
An AS is a connected group of one or more IP prefixes run by one or more network operators which has a SINGLE and CLEARLY DEFINED routing policy.
Que más o menos sería:
Un sistema autónomo AS es un grupo de uno o más prefijos de red controlados por uno o más operadores de red que tiene una ÚNICA política de enrutamiento que además está CLARAMENTE DEFINIDA.
Una definición más simple sería «una empresa u organización que tiene un conjunto de redes».
Los sistemas autónomos suelen tener asignado un número por parte del IANA que se utiliza en muchas operaciones administrativas y que (lógicamente) se llama número de sistema autónomo. Estos números tienen 32 bits y se escriben como un solo número decimal, el cual puede ir de 0 a (2 a la 32)-1.
Protocolos de enrutamiento interno
Son protocolos dinámicos, es decir, que configuran automáticamente todas las rutas liberando al administrador del trabajo. Los protocolos de enrutamiento interno están pensados para usarse dentro de un sistema autónomo. Esto es así porque están pensados para entornos en los que conocemos toda la red, precisamente por ser nuestra red.
Estos protocolos suelen llamarse a veces IGPs (Interior Gateway Protocols)
Protocolos de enrutamiento externo
También son dinámicos pero están pensados para interconectar nuestro AS con otros AS.Estos protocolos suelen llamarse a veces EGPs (Exterior Gateway Protocols). Más abajo veremos como funciona BGP, el protocolo EGP por excelencia.
El enrutamiento sin clase.
Se llama enrutamiento sin clase o CIDR (Classless InterDomain Routing) al enrutamiento que no tiene en cuenta para nada si una dirección es de clase A, B o C. Durante todo este curso no le hemos dado ninguna importancia y de hecho hemos trabajado con máscaras como /18 o /23. Sin embargo, en el pasado las clases A,B o C tenían muchísima importancia, por lo que a veces en los temarios se resalta esta diferencia, pero esto es solo por motivos históricos. Los protocolos modernos de enrutamiento no tienen en cuenta para nada la clase de una IP y podemos tener direcciones como 10.65.128.0/28 (a esta forma de escribir la IP, la barra y los bits de la máscara se le denomina «notación CIDR»).
La subdivisión de redes y el uso de máscaras de longitud variable (VLSM).
Este proceso de construcción de redes IP surgió por la necesidad de aprovechar al máximo las direcciones IP. Hoy en día se consideran algo a extinguir aunque en su momento fue una técnica utilizadísima para aprovechar al máximo las asignaciones.
Observemos la figura siguiente:
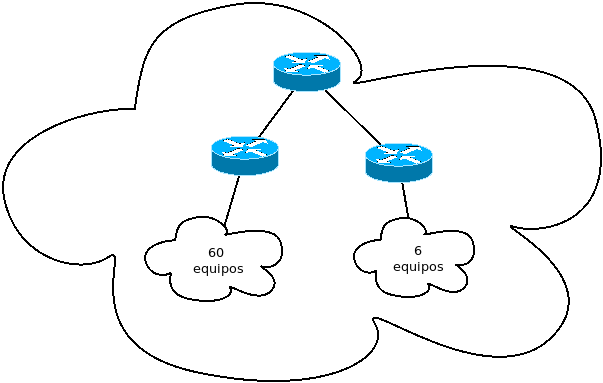
Supongamos que queremos comprobar un bloque de direcciones IP y que además queremos hacer dos subredes separadas, tal y como indica la figura. Si además resulta que no hay muchas direcciones IP y queremos ahorrar resulta que ocurre lo siguiente (nótese que en el ejemplo todo está ajustadísimo):
Supongamos que compramos el prefijo 161.1.1.0/24. Tenemos 8 bits de host y podemos direccionar 254 equipos.
Dividimos en subredes y entonces a la izquierda tendremos 161.1.1.<01>xxxxxx/26 y la derecha 161.1.1<10>xxxxxx/26. Obsérvese que el último byte lo hemos puesto en binario y hemos asignado 01 a la subred izquierda y 10 a la subred derecha.
Al hacer la división en la parte izquierda tenemos 6 bits que nos da para direccionar hasta 2 a la 6 (-2) o sea 62 equipos, que es más que suficiente.
Al hacer la división ocurre que en la parte derecha también tenemos hasta 62 posibles equipos, sin embargo nos sobran muchísimas direcciones. Si necesitásemos más equipos no tendríamos mucho margen para meterlos en la subred izquierda y es posible que no nos interese ponerlos en la subred derecha. Conclusión: se desperdician direcciones en la zona derecha.
Resolución de subredes con VLSM
Una vez que hemos visto que determinadas situaciones pueden dar lugar a desperdicios, vamos a ver como usar máscaras de longitud variable nos ayuda a reducir el desperdicio a la vez que aprovechamos mejor el espacio de direcciones.
Supóngase el mismo prefijo de antes: 161.1.1.0/24. Supongamos ahora que necesitamos crear 4 subredes que tienen respectivamente 10, 45, 29 y 70 hosts, con un total de 154 host. Se debe empezar ordenando las subredes por tamaño, lo que daría a empezar a resolver primero la red de 60 hosts, despues la de 45, luego 29 y finalmente 10.
Cabe destacar que ahora en el proceso va a ocurrir que en cada paso nos vamos a apoyar en la IP del paso anterior.
Subred de 70 host
Tenemos la IP 161.1.1.0 y vamos a fabricar la subred para alojar a 60 host. Esto implica que necesitamos 7 bits (recordemos que 2 a la 7 es 128 y restando 2 nos quedan hasta 126 host) . A continuación ponemos el prefijo y la máscara tanto en decimal como en binario:
Primer byte |
Segundo byte |
Tercer byte |
Cuarto byte |
|---|---|---|---|
161 |
1 |
1 |
0 |
10100001 |
00000001 |
00000001 |
00000000 |
255 |
255 |
255 |
0 |
11111111 |
11111111 |
11111111 |
00000000 |
Como vemos, nos han dejado el cuarto byte. Todas nuestras operaciones estarán entonces en el cuarto byte, lo que implica que todas las IP empezarán por 161.1.1.xxx y todas las máscaras empezarán por 255.255.255.xxx.
Esta primera red es la más grande así que se queda con un bit más de prefijo (en vez de /24 será /25) y utilizará los 7 bits restantes para poder poner direcciones. En la tabla siguiente indicamos el último byte de la máscara y como queda este último byte:
0 |
x |
x |
x |
x |
x |
x |
x |
Decimal |
|---|---|---|---|---|---|---|---|---|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Máscara |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
2 |
… |
||||||||
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
126 (Última) |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
127 (Broadcast) |
Esto significa que esta primera red tiene estos parámetros:
Dirección de red 161.1.1.0
Máscara 255.255.255.128 o /25
Primera IP asignable 161.1.1.1
Última IP asignable: 161.1.1.126
Dirección de broadcast: 161.1.1.127
Como vemos, se necesitaban 60 IPs y se han asignado 128.
Obsérvese que la última IP es la 161.1.1.127, da igual que sea la de broadcast. En el paso siguiente empezaremos por la siguiente IP que es la 161.1.1.128.
Subred de 45 hosts
Partimos de la IP 161.1.1.128/25 (o 255.255.255.128). Como necesitamos 45 nodos reservaremos 6 bits de host y nos queda uno de subred. Ahora dividimos dicha IP 161.1.1.128 en una nueva subred. La tabla siguiente ilustra el proceso de como manejamos los últimos 8 bits para conseguir lo que queremos:
Fijado |
Subred |
H |
H |
H |
H |
H |
H |
|
|---|---|---|---|---|---|---|---|---|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Ultimo byte de la IP |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
Último byte de la másc.(192) |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Direc. de red |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
Primera IP asignable |
1 |
0 |
x |
x |
x |
x |
x |
x |
… |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
Última IP asignable |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
Broadcast |
Esta red tiene estos parámetros:
Dirección de red: 161.1.1.128
Máscara de red 255.255.255.192 o /26
Primera IP asignable: 161.1.1.129
Última IP asignable: 161.1.1.190
Dirección de broadcast: 161.1.1.191
Se necesitaban 45 hosts y se han asignado 64.
El siguiente paso lo haremos partiendo de la siguiente IP que es la 161.1.1.192
Subred de 29 hosts
Partimos de la IP 161.1.1.192/26 y necesitamos 29 hosts, lo que requiere 5 bits de host y uno de subred. De nuevo indicamos a continuación como queda el último byte en esta red:
Fijado |
Fijado |
Subred |
H |
H |
H |
H |
H |
|
|---|---|---|---|---|---|---|---|---|
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
Ultimo byte de la IP |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
Último byte de la másc.(224) |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
Direc. de red |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
Primera IP asignable (193) |
1 |
1 |
0 |
x |
x |
x |
x |
x |
… |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
0 |
Última IP asignable (222) |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
Broadcast (223) |
Dirección de red: 161.1.1.192
Máscara de red 255.255.255.224 o /27
Primera IP asignable: 161.1.1.193
Última IP asignable: 161.1.1.222
Dirección de broadcast: 161.1.1.223
Se necesitaban 29 IPs y se han asignado 32.
El siguiente paso lo empezaremos a partir de la siguiente IP, que es 161.1.1.224.
Subred de 10 hosts
Partimos de 161.1.1.224/27 y necesitamos 10 hosts, así que tomaremos 4 bits de host. En la tabla siguiente vemos como queda el último byte:
Fijado |
Fijado |
Fijado |
Subred |
H |
H |
H |
H |
|
|---|---|---|---|---|---|---|---|---|
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
Ultimo byte de la IP (224) |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
Último byte de la másc.(240) |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
Direc. de red |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
Primera IP asignable (225) |
1 |
1 |
1 |
x |
x |
x |
x |
x |
… |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
Última IP asignable (239) |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
Broadcast (240) |
Así que ésta ultima red tiene estos parámetros:
Dirección de red 161.1.1.224.
Máscara 255.255.255.240 o /28
Primera IP asignable 161.1.1.225.
Ultima IP asignable 161.1.1.239
Dirección de broadcast 161.1.1.240
Se necesitaban 10 IPs y se han asignado 16.
Cálculo del desperdicio y comparación con subredes
Otro VLSM resuelto
Dada una subred con prefijo 64.1.1.0/24 construir un esquema de direcciones para 4 subredes que tienen respectivamente 41, 19, 12 y 3.
Partimos de esto:
Byte 3 |
Byte 2 |
Byte 1 |
Byte 0 |
Concepto |
|---|---|---|---|---|
64 |
1 |
1 |
0 |
Dirección IP de base |
01000000 |
00000001 |
00000001 |
00000000 |
Dirección IP binaria |
RRRRRRRR |
RRRRRRRR |
RRRRRRRR |
HHHHHHHH |
División de base |
11111111 |
11111111 |
11111111 |
00000000 |
Máscara de base |
La primera sala requiere 6 bits, así que en esta sala la situación es así:
Byte 3 |
Byte 2 |
Byte 1 |
Byte 0 |
Concepto |
|---|---|---|---|---|
64 |
1 |
1 |
0 |
Dirección IP de base |
01000000 |
00000001 |
00000001 |
00000000 |
Dirección IP binaria |
RRRRRRRR |
RRRRRRRR |
RRRRRRRR |
SS HHHHHH |
División de base |
11111111 |
11111111 |
11111111 |
00000000 |
Máscara anterior |
11111111 |
11111111 |
11111111 |
**11**000000 |
Nueva máscara |
01000000 |
00000001 |
00000001 |
00 000000 |
IP red: 64.1.1.0 |
01000000 |
00000001 |
00000001 |
00 000001 |
IP 1: 64.1.1.1 |
… |
||||
01000000 |
00000001 |
00000001 |
00 111110 |
Últ IP: 64.1.1.62 |
01000000 |
00000001 |
00000001 |
00 111111 |
Broadcast: 64.1.1.63 |
Debemos continuar a partir de la 64.1.1.64/26 y necesitamos asignar IP a 19 equipos. Nos basta con 5 bits. Indicamos solo la solución a las restantes salas y se deja como ejercicio el calcular si se ha hecho bien.
El protocolo RIPv2; comparación con RIPv1.
RIPv1 y RIPv2 se caracterizan por:
Ambos son protocolos de enrutamiento interior.
Se basan en un mecanismo llamado «vector distancia» que básicamente cuenta la cantidad de saltos para llegar a una ruta.
En los protocolos basados en vector distancia ocurre lo siguiente: si para ir a una red hay dos caminos y uno implica pasar por 3 router y otro camino implica pasar por 6 routers se asume que el segundo camino es peor por tener una «distancia» mayor. Sin embargo esto podría ser falso: imaginemos que el camino con métrica 3 está basado en líneas ADSL de 3Mb/s y el de métrica 6 pasa por fibras ópticas de 800Mb/s.
RIPv1 no soportaba subredes, lo que a día de hoy lo hace prácticamente inútil. Además estaba pensado para usar clases A, B y C, y de hecho no envía máscaras de red.
Configuración y administración de RIPv1.
Debido al inminente final del curso, se ha decidido ignorar este punto para ahorrar tiempo y dedicarlo a puntos más actuales del temario. Un factor fundamental para su obsolescencia es que RIP exige usar máscaras de clase A, B o C (es decir /8, /16 y /24) para sus rutas, lo que hoy en día lo hace completamente inútil
Configuración y administración de RIPv2.
RIP es un protocolo basado en un algoritmo de «vector-distancia». Básicamente, lo que hace este algoritmo es «contar saltos»: esto significa que si hay varios caminos a una cierta red y un camino conlleva «3 saltos» se dice que dicha ruta es mejor que una que necesite «5 saltos».
La operativa básica consiste en ejecutar dos cosas en cada uno de los router:
El comando
router rip.El comando
networkpara cada una de las redes que el router va a anunciar a sus vecinos.
Observa la figura siguiente:
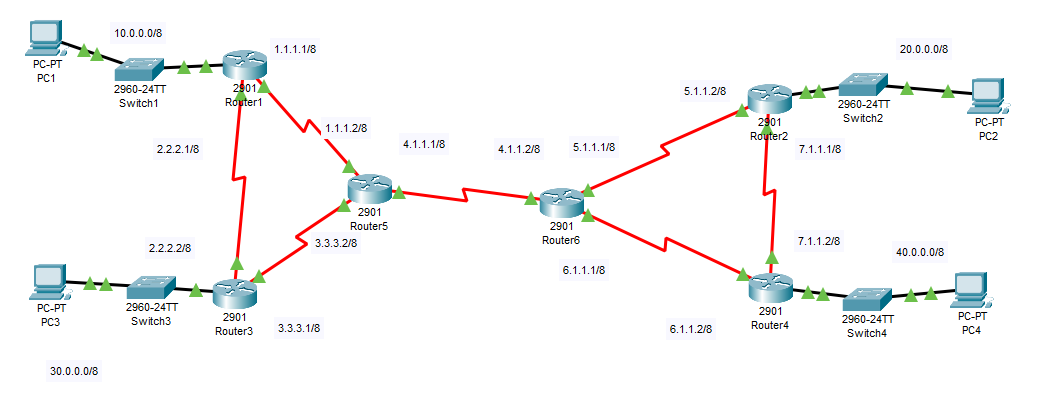
En dicha red hay una interconexión compleja de routers. Calcular todos los posibles caminos sería demasiado laborioso. Observa como podemos usar los comandos apropiados para que los routers se autoconfiguren.
En primer lugar, el router 5 no necesita aprender la topología de la derecha, podemos ponerle una ruta por defecto de esta manera:
enable
configure terminal
ip route 0.0.0.0 0.0.0.0 4.1.1.2
Podemos hacer exactamente lo mismo con el router 6 y hacer esto:
enable
configure terminal
ip route 0.0.0.0 0.0.0.0 4.1.1.1
También podríamos configurar RIP de la manera normal y lo indicamos a continuación. Empezaremos por el «área» izquierda, que contiene los router 0, 1 y 2.
Router 1 con RIP
Comandos necesarios:
enable
configure terminal
router rip
version 2
network 2.0.0.0
network 1.0.0.0
network 10.0.0.0
Router 3 con RIP
Comandos necesarios:
enable
configure terminal
router rip
version 2
network 2.0.0.0
network 3.0.0.0
network 30.0.0.0
Router 5 con RIP
Comandos necesarios:
enable
configure terminal
router rip
version 2
network 1.0.0.0
network 3.0.0.0
En este punto el área izquierda debe tener autoconfiguradas sus rutas. A continuación configuramos el «área» derecha, que involucra a los router 2, 4 y 6.
Router 6 con RIP
Comandos necesarios:
enable
configure terminal
router rip
version 2
network 5.0.0.0
network 6.0.0.0
Router 2 con RIP
Comandos necesarios:
enable
configure terminal
router rip
version 2
network 20.0.0.0
network 5.0.0.0
network 7.0.0.0
Router 4 con RIP
Comandos necesarios:
enable
configure terminal
router rip
version 2
network 40.0.0.0
network 6.0.0.0
network 7.0.0.0
Y llegado este punto, el área derecha también funciona y permite que la información fluya dentro de esa zona. Sin embargo ¿qué ocurre si intentamos hacer ping desde un ordenador del área izquierda a uno del área derecha? Ocurre que NO FUNCIONA
Como ocurre que los router centrales usan rutas estáticas necesitamos que dicha información sobre rutas estáticas SE PROPAGUE para que otros router en la red usen los router 5 y 6 como routers por defecto. Para ello, hacemos lo siguiente en ambos router 5 y 6:
enable
configure terminal
router rip
version 2
redistribute static
El comando passive-interface <interfaz>
Si ponemos Packet Tracer en modo simulación veremos que los router hacen anuncios por todas las redes que tienen conectadas. Sin embargo nosotros sabemos que en algunas interfaces no hay otros router conectados. Si deseamos evitar tráfico innecesario en la red podemos indicar al router que una cierta interfaz actuará en modo pasivo y que por tanto no enviará anuncios por dicha tarjeta. Esto mejora el rendimiento general de la red.
El comando redistribute static
En la vida real un router no tiene por qué tener todas las rutas configuradas dinámicamente. Es posible que en algunos casos el administrador haya configurado rutas estáticas. Si no hacemos nada, el router no redistribuirá dichas rutas estáticas y por tanto puede haber routers que no encuentren los caminos correctos a ciertas redes.
El comando redistribute static ordena al router que también anuncie dichas rutas estáticas a otros nodos. Como nota curiosa, no solo pueden redistribuirse rutas estáticas sino también información de otros protocolos de enrutamiento.
Advertencia
El comando redistribute static en OSPF solo acepta redes «con clase». Para que OSPF redistribuya rutas por defecto se usa default-information originate
El comando ip route 0.0.0.0 0.0.0.0 <interfaz o IP>
Lo conocemos de fechas anteriores. Se utiliza para indicar una ruta por defecto.
Adaptabilidad en OSPF
Una línea serie (llamadas «Serial0/1/0» o similar en Packet Tracer) puede modificarse parq que funcione a otras velocidades. Por defecto funcionan a 2.000.000 bps o 2Mbps. En toda línea serie hay una que marca la velocidad de reloj y podemos modificar la velocidad de dicho reloj usando el comando clock rate.
Si entramos en una línea serie, reducimos la velocidad usando por ejemplo clock rate 56000 e informamos a los procesos de enrutamiento de que el ancho de banda ha cambiado con un comando bandwidth 56 (el ancho de banda se escribe en kbps) y esperamos a que OSPF se actualice, podremos ver como un router elige un camino más largo. Puede usarse el comando de administrador show ip ospf interfaces para ver el coste que OSPF asigna a una línea.
Diagnóstico de incidencias en RIPpv2.
Lo habitual es que todo funcione correctamente. Sin embargo, existen varios comandos que nos van a permitir comprobar si hay errores de cualquier tipo:
debug ip routingEste comando activa el modo depuración. Una vez lanzado, podremos ver los distintos mensajes de actualización de rutas que afectan a este router (lo cual nos permitirá ver si otros router o este mismo están propagando rutas incorrectas)show ip routeAl lanzarlo veremos en la consola las distintas rutas que este router conoce. Además se nos informará de si son rutas aprendidas, configuradas estáticamente y si tenemos interfaces conectadas a dichas redes.show logMuestra el registro general de actividad lo que puede permitir detectar otros errores que sin ser problemas de enrutamiento sí den lugar a errores de comunicación.
Los protocolos de enrutamiento estado-enlace
Son protocolos de enrutamiento dinámico que no utilizan el recuento de saltos para determinar cual es el mejor camino, sino que utilizan el estado del enlace, es decir, su ancho de banda. Este mecanismo es, de media, mucho mejor que el «vector distancia» usado por los protoclos que hemos visto antes.
Con toda probabilidad el protolo de estado-enlace más usado es OSPF.
Configuración y administración en OSPF.
Proceso básico
En esencia el proceso de funcionamiento es muy parecido al de RIP. Solo usaremos estos comandos:
El comando
router ospf <número de proceso>activará el enrutamiento OSPF.El comando
network <ip de red> <wildcard> <area>indica al router la red o redes que debe anunciarse. Hay que fijarse bien en que OSPF utiliza wildcards y no máscaras de red estándar
Áreas
En RIP veíamos que si interconectamos un conjunto grande de routers puede ocurrir que haya:
Muchas actualizaciones, lo que colapsa la red.
Puede ocurrir que dependiendo de la topología se pasen grandes tablas de enrutamiento hacia «zonas» o «áreas» que no la necesitan.
OSPF integra el concepto de áreas. Así que podremos configurar redes como pertenecientes a un cierto «número de área»
LSDB
Es la Link State DataBase, o base de datos del estado del enlace. OSPF tiene en cuenta los anchos de banda de los enlaces y esa información viaja siempre junto con la tabla de rutas.
Esta base de datos puede ser grande, pero contiene todos los detalles que necesitan todos los router para autoconfigurarse.
LSA
Link State Advertisement o «Anuncio del estado del enlace». Son mensajes que se intercambian periódicamente los routers para comprobar si todo funciona y a qué velocidad.
Adyacencias
Se dice que un enlace es «punto a punto» cuando un router solo tiene un vecino al otro lado del enlace.
Se dice que un enlace es «de acceso múltiple» cuando en un enlace un router puede tener varios vecinos.
Router designado, de backup y DROthers
Router designado es el router ganador en las elecciones OSPF de un enlace multiacceso que se va a convertir en el que controla la información de ese enlace.
Router backup es el router que tomará el control si observa que el designado cae.
DROther son todos aquellos routers que han perdido las elecciones y que por tanto no propagan información dentro del área (salvo los mensajes HELLO)
Es posible ver el estado de un router usando el comando (desde el modo administrador) show ip ospf interfaces
Router ASBR
OSPF también puede usar para enrutar hacia otros sistemas autónomos. En ese caso, el router ASBR es el Autonomous System Border Router o «router frontera».
Router ABR
Se llama Area Border Router al router que interconecta dos áreas.
Diagnóstico de incidencias en OSPF.
Podemos usar exactamente los mismos comandos que hemos visto antes y que volvemos a reproducir a continuación.
debug ip routingEste comando activa el modo depuración. Una vez lanzado, podremos ver los distintos mensajes de actualización de rutas que afectan a este router (lo cual nos permitirá ver si otros router o este mismo están propagando rutas incorrectas)show ip routeAl lanzarlo veremos en la consola las distintas rutas que este router conoce. Además se nos informará de si son rutas aprendidas, configuradas estáticamente y si tenemos interfaces conectadas a dichas redes.show logMuestra el registro general de actividad lo que puede permitir detectar otros errores que sin ser problemas de enrutamiento sí den lugar a errores de comunicación.
Configuración y administración de BGP
BGP (Border Gateway Protocol) es el principal protocolo EGP. El proceso es muy sencillo pero con un cambio importante.
Todos los router deben anunciar las redes con equipos pero no deben anunciar las redes de interconexión con otros routers. Esto se hace con el comando
network <dirección_ip> mask <máscara_de_red>. Obsérvese que volvemos a usar máscaras de red y no wildcards.Cada router debe tomar nota de la IP de sus routers vecinos e identificarlos con el comando
neighbor <ip_vecino> remote-as <número_de_AS>Una vez hecho esto, BGP empezará a funcionar y podremos comprobarlo usando el comando
show ip bgp.
Configuración y administración de protocolos de enrutamiento propietarios.
Existen otros protocolos como EIGRP que son propiedad específica de Cisco. Aunque pueden ser muy eficientes esta clase de protocolos nos vincula por completo a un solo fabricante y suele ser preferible ceñirse a protocolos abiertos. En este curso no hemos impartido EIGRP por falta de tiempo.